

Optimizar una base de datos PostgreSQL puede marcar la diferencia entre una aplicación ágil y una que frustra a los usuarios. El «tuning» o ajuste fino de PostgreSQL implica configurar adecuadamente los parámetros del sistema, optimizar consultas SQL y gestionar bien los recursos del servidor.
¿Qué es el tuning en PostgreSQL?
El tuning es el proceso de ajustar configuraciones del motor de base de datos para lograr un rendimiento óptimo. PostgreSQL, por defecto, viene con parámetros conservadores que priorizan la estabilidad, pero no necesariamente el máximo rendimiento.
¿Por qué es importante tunear PostgreSQL?
- Reduce el tiempo de respuesta de las consultas.
- Disminuye el uso innecesario de recursos.
- Evita bloqueos, cuellos de botella y caídas de servicio.
- Mejora la escalabilidad y el manejo de carga concurrente.

Arquitectura de PostgreSQL: ¿Cómo funciona internamente?
El servidor PostgreSQL tiene una estructura clásica de los sistemas de gestión de bases de datos relacionales (RDBMS). Esta incluye:
- Memoria compartida (shared pool)
- Procesos en segundo plano (background processes)
- Directorio de datos (estructura física de la base de datos)
A estas estructuras de memoria y procesos se les conoce como la Instancia PostgreSQL.
El proceso funciona de la siguiente manera:
- El cliente envía una petición al servidor postmaster para abrir una sesión.
- El servidor postmaster, que escucha conexiones entrantes, crea un proceso servidor dedicado a ese cliente.
- Cliente y servidor quedan comunicándose peer-to-peer.
- Las peticiones SQL son procesadas utilizando buffers compartidos y procesos background.
- Los datos físicos se almacenan en el directorio de datos de PostgreSQL.
- Cada buffer en memoria tiene su contraparte en disco. Si un dato no está en memoria, se carga desde disco, y esa imagen en memoria se denomina buffer.
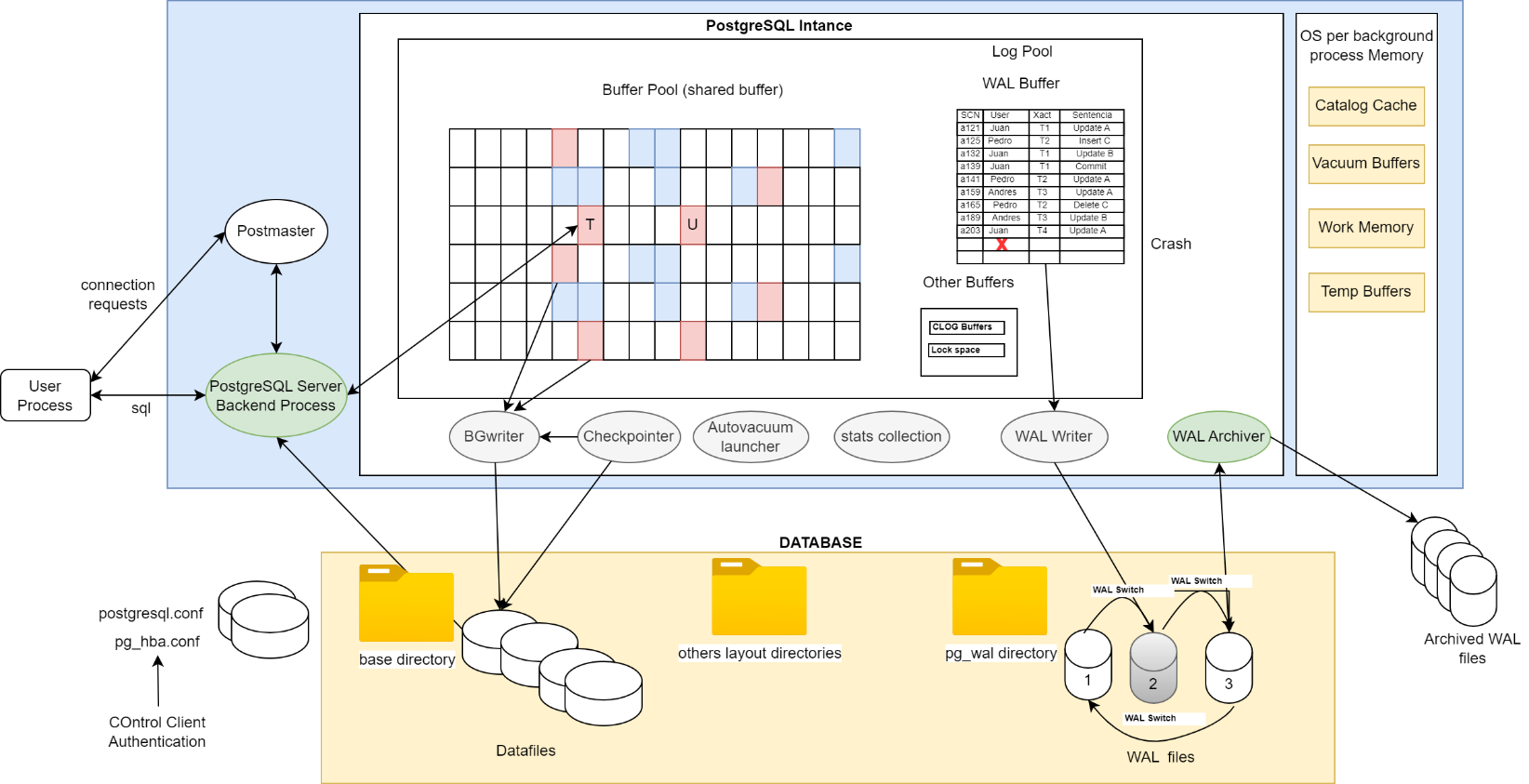
Ilustración 1 Arquitectura PostgreSQL
Parámetros clave para tunear PostgreSQL
| Parámetro | ¿Qué hace? | Recomendación inicial |
|---|---|---|
shared_buffers |
Memoria que PostgreSQL usa para cache interno | 25-40% de la RAM del servidor |
work_mem |
Memoria por operación (JOIN, sort, hash, etc.) | 4-64 MB por conexión |
effective_cache_size |
Estimación del cache del sistema operativo disponible para PostgreSQL | 50-75% de la RAM total |
maintenance_work_mem |
Memoria usada para VACUUM, CREATE INDEX, etc. | 128MB-2GB según carga |
wal_buffers |
Buffer de escritura para WAL | Al menos 16MB |
max_connections |
Número máximo de conexiones simultáneas | 100-300 según concurrencia esperada |
Tuning según tipo de carga de trabajo
| Tipo de carga | Parámetros clave | Consideraciones |
|---|---|---|
| OLTP | work_mem, max_connections, wal_buffers |
Transacciones rápidas y concurrentes |
| OLAP | parallel_workers, effective_cache_size |
Consultas complejas y grandes volúmenes |
| Lotes (Batch) | maintenance_work_mem, wal_compression |
Procesamiento intensivo de datos |
Herramientas para tuning PostgreSQL
EXPLAIN (ANALYZE): Muestra el plan de ejecución de una consulta.pg_stat_statements: Extensión para ver las consultas más pesadas.auto_explain: Log de planes de ejecución lentos automáticamente.pgBadger: Analiza los logs para detectar cuellos de botella.pgtune: Generador automático de parámetros basado en recursos del servidor.
Errores comunes al hacer tuning
- Ajustar
work_memdemasiado alto sin considerar el número de conexiones. - Desactivar
autovacuumpensando que mejora el rendimiento. - Hacer cambios sin medir impacto con herramientas.
- No considerar el sistema operativo o hardware en uso.
Caso práctico: Mejora de rendimiento real
| Aspecto | Antes del Tuning | Después del Tuning |
|---|---|---|
| Tiempo de respuesta | 8–10 segundos | Menos de 1 segundo |
| Carga del sistema | Alta en CPU y disco | Reducción del 40% en carga de CPU |
| Parámetros ajustados | No optimizados | shared_buffers, work_mem, autovacuum configurados correctamente |
PostgreSQL y nuevas versiones
Desde PostgreSQL 15 en adelante, hay mejoras importantes como:
- Compresión avanzada en WAL (
wal_compression). - Mejores estrategias de
autovacuum. - Mayor paralelización en consultas complejas.
Cómo ajustar el rendimiento de PostgreSQL
El tuning de PostgreSQL depende del tipo de carga que maneje tu base de datos: puede ser un sistema OLTP (orientado a transacciones), un sistema DSS (consultas analíticas), o un sistema batch. Cada uno requiere configuraciones distintas, especialmente en cómo se maneja la memoria, los índices y la concurrencia.
1. Diseño de Base de Datos
Un buen diseño es clave para el rendimiento:
-
Indexar correctamente: usa índices en columnas que se filtran con frecuencia (
WHERE). Evita indexar todo: cada índice cuesta espacio y tiempo de escritura. -
Particionar tablas grandes puede acelerar consultas que filtran por rangos (fechas, IDs, etc.).
-
Diseño relacional coherente: evitar redundancias y aplicar claves foráneas bien pensadas.
2. Hardware
El rendimiento de PostgreSQL depende directamente del hardware. Aquí un resumen:
| Componente | Rol | Recomendaciones |
|---|---|---|
| CPU | Cálculo de planes de ejecución, agregaciones, joins. | Optimiza consultas antes de escalar CPU. |
| RAM | Almacena datos en caché. | Asigna suficiente para buffers y consultas. |
| Disco (I/O) | Almacén de datos y WAL. | Usa SSD y distribuye cargas en varios discos. |
| Red | Flujo de datos entre capas. | Minimiza viajes de datos usando funciones almacenadas. |
3. El sistema operativo
El sistema operativo es el puente entre PostgreSQL y el hardware. Algunos puntos clave:
-
Configuraciones TCP: si las conexiones se caen por inactividad (
Connection reset by peer), ajusta los valorestcp_keepalivedel sistema. -
Lectura/escritura eficiente: configura bloques grandes para operaciones de I/O intensas.
-
Linux vs Windows:
-
Linux: señales TCP cada 75s.
-
Windows: cada 1s.
-
Ambos pueden modificarse para evitar cierres de conexión.
-
4. Parámetros de configuración de PostgreSQL
PostgreSQL ofrece muchos parámetros configurables. Aquí te resumo los principales:
a) Conexiones
-
max_connections: define el número máximo de conexiones simultáneas.-
Recomendación:
max(4 * núcleos CPU, 100)
-
b) Memoria
| Parámetro | Uso | Recomendación |
|---|---|---|
shared_buffers |
Memoria compartida entre procesos. | Hasta el 25% de la RAM. |
work_mem |
Memoria por operación de consulta (ordenar, hash). | Mínimo 4MB. Se aplica por operación. |
maintenance_work_mem |
Usado en VACUUM, CREATE INDEX, etc. | 1GB o más. |
temp_buffers |
Buffers temporales por sesión. | Ajustar por número de sesiones. |
wal_buffers |
Buffer para logs WAL antes de escribirlos. | Dejar en -1 (auto), suele ser ~3% de shared_buffers. |
5. Optimización de WAL (Write-Ahead Logging)
PostgreSQL registra todo cambio en archivos WAL antes de aplicarlo en disco. Puedes ajustar estos parámetros:
| Parámetro | Rol | Comentario |
|---|---|---|
fsync |
Fuerza escritura inmediata a disco. | Activado por defecto. Mejora durabilidad. |
commit_delay |
Espera antes de escribir WAL para agrupar commits. | Útil para rendimiento, pero riesgo en caso de fallo. |
checkpoint_timeout |
Tiempo máximo entre checkpoints. | Por defecto: 5 minutos. |
checkpoint_completion_target |
Distribuye carga del checkpoint. | Valor por defecto 0.9; no se recomienda cambiar. |
max_wal_size / min_wal_size |
Controlan tamaño total de WAL. | Reemplazan checkpoint_segments desde v9.5. |
Lea lo último de nuestro blog: «La familia de productos de bases de datos Oracle».

